Merge PDF
Last modified by Outhman Moustaghfir on 2024/09/09 11:46
Overview
The Merge PDF Connector is designed to merge multiple PDF files into a single output PDF file. It takes a list of PDF files as input and combines them in the order provided, ensuring that each file starts on a new page in the output file. The connector handles file verification, ensuring only valid PDF files with content are merged, and supports error handling for missing or corrupted files.

Functionality
- Input: A list of PDF files to merge.
- Output: A single merged PDF file.
- Error Handling: Logs and skips files that are either empty, missing, or invalid.
- Memory Management: Supports different memory usage settings to handle large file merges efficiently
Main Features
File Validation:
- Each input PDF file is checked for existence and content (i.e., it must contain at least one page).
- If a file is empty or cannot be found, the connector logs a warning and skips it.
PDF Merging:
- Uses Apache PDFBox’s PDFMergerUtility to merge files.
- Each valid input file is added to the merger, and the documents are combined in the provided order.
- The output is saved to a specified location.
Error Handling:
- For each invalid or unreadable PDF file, a detailed error is logged, and the connector continues with the next file.
- Any failure during the merge process is captured and rethrown as an IOException.
Performance Optimization:
- The connector supports memory management using MemoryUsageSetting to prevent excessive memory usage during large file merges. This setting can be customized to use either main memory or temporary files, depending on the use case.
Example Usage
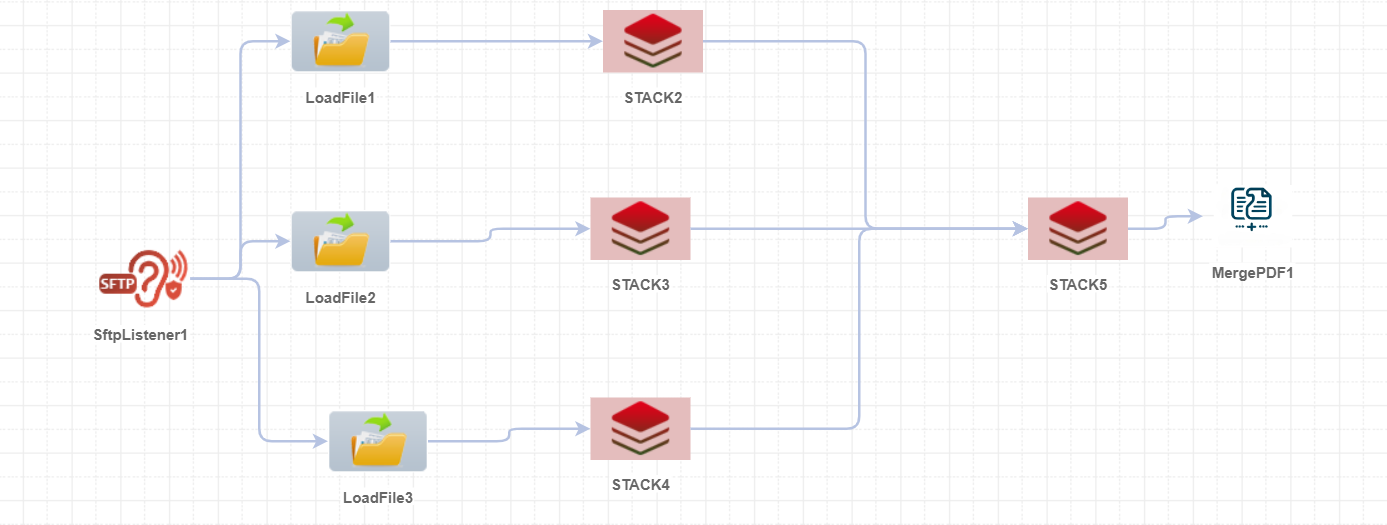
For this example, the input files are those that have been accumulated in the connector stack5, and the output will be a single file that combines all the input files from the list.